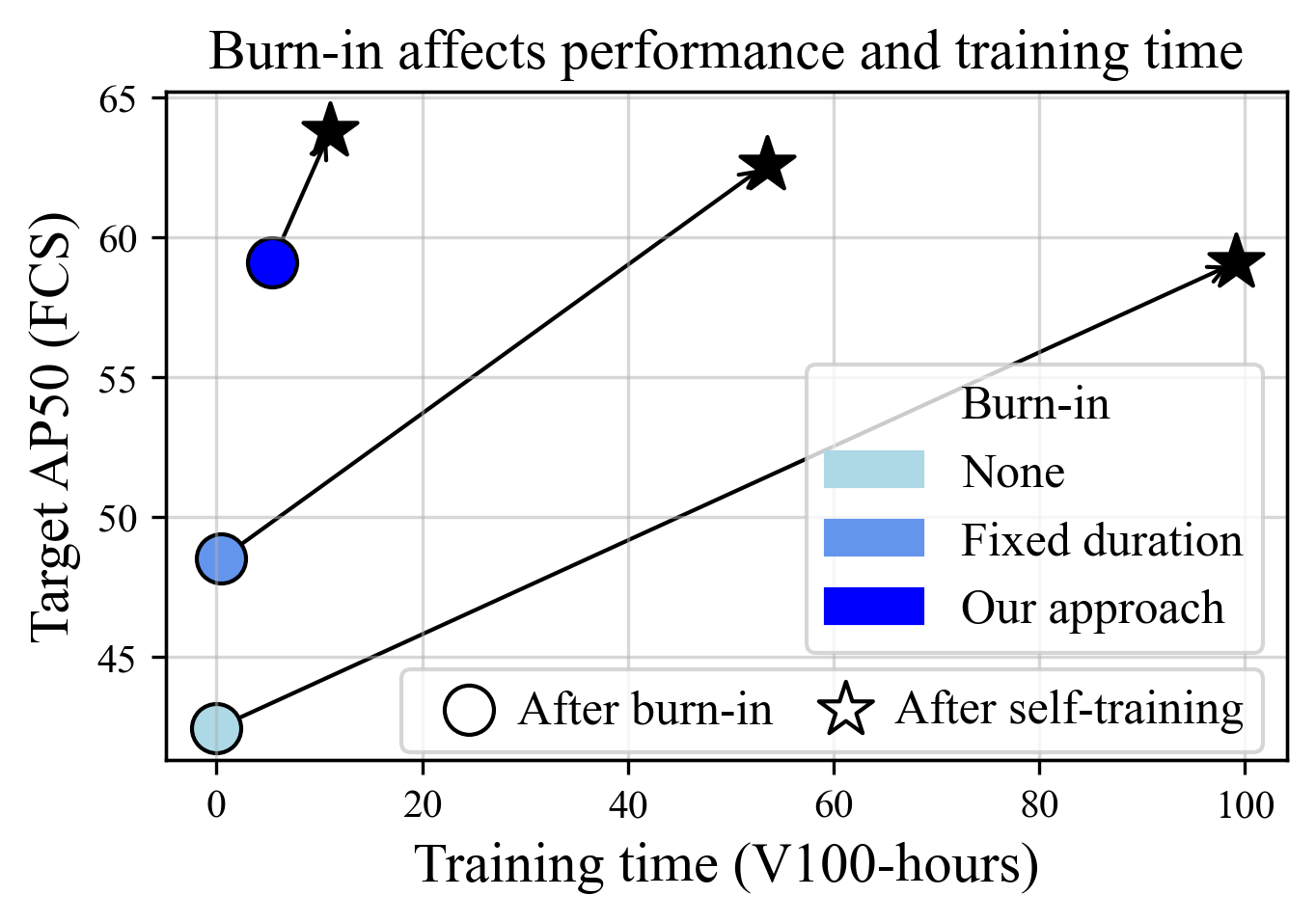
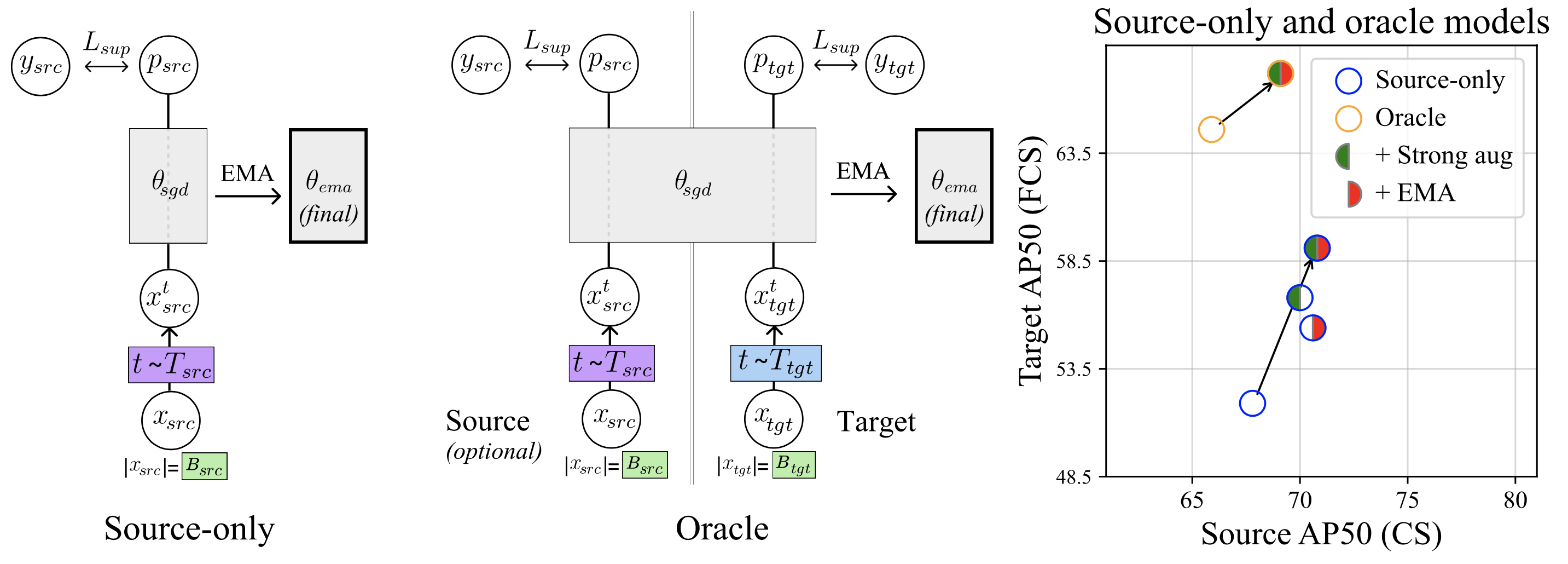
We find that in prior work, source-only and oracle models are consistently constructed in a way that does not properly
isolate domain-adaptation-specific components, leading to misattribution of performance improvements.
We show that including these components
significantly improves both source-only and oracle model performance (+7.2 and +2.6 AP50 on Foggy Cityscapes, respectively).
Practically, this
means that source-only and oracle models are significantly stronger than previously thought, setting more challenging
performance targets for algorithm developers.
Experimental Results
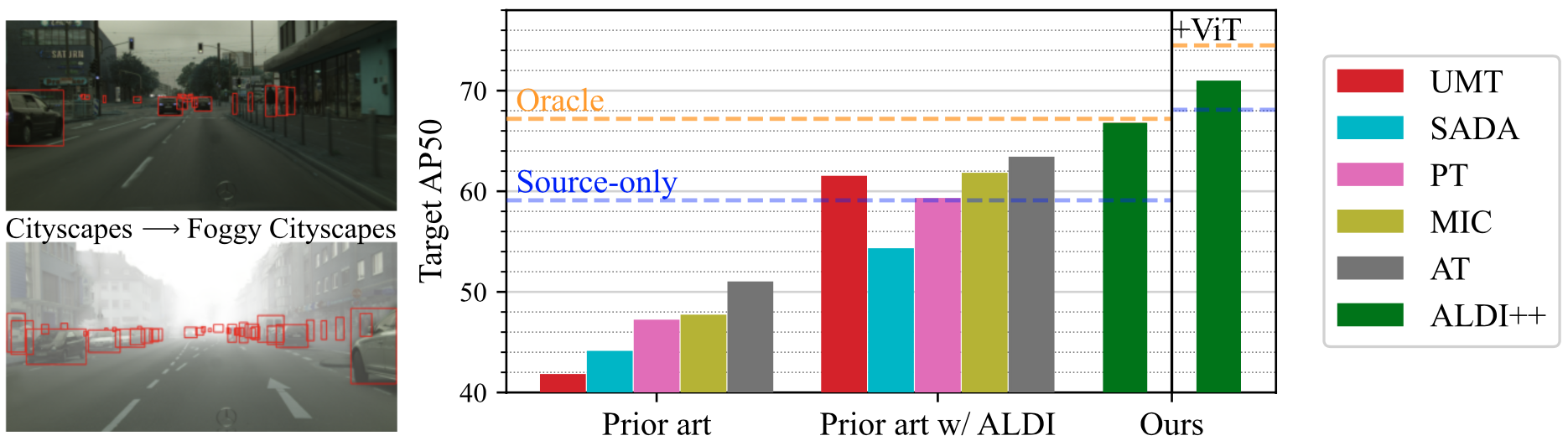
Our protocol offers researchers the opportunity to rigorously compare to strong baselines.
Not all existing methods outperform a fair source-only baseline. For those that do, there is still
room for improvement, especially with stronger backbones like ViT.